Query Stats
General Workload analysis
The Query Stats dashboard summarizes workload characteristics and surfaces high cost queries so you can
prioritize tuning and capacity decisions. This dashboard is your primary tool for understanding which
queries consume the most resources and where optimization efforts will have the greatest impact.
 Query Stats Dashboard showing workload overview and query statistics
Query Stats Dashboard showing workload overview and query statistics
Dashboard Sections
Workload Overview
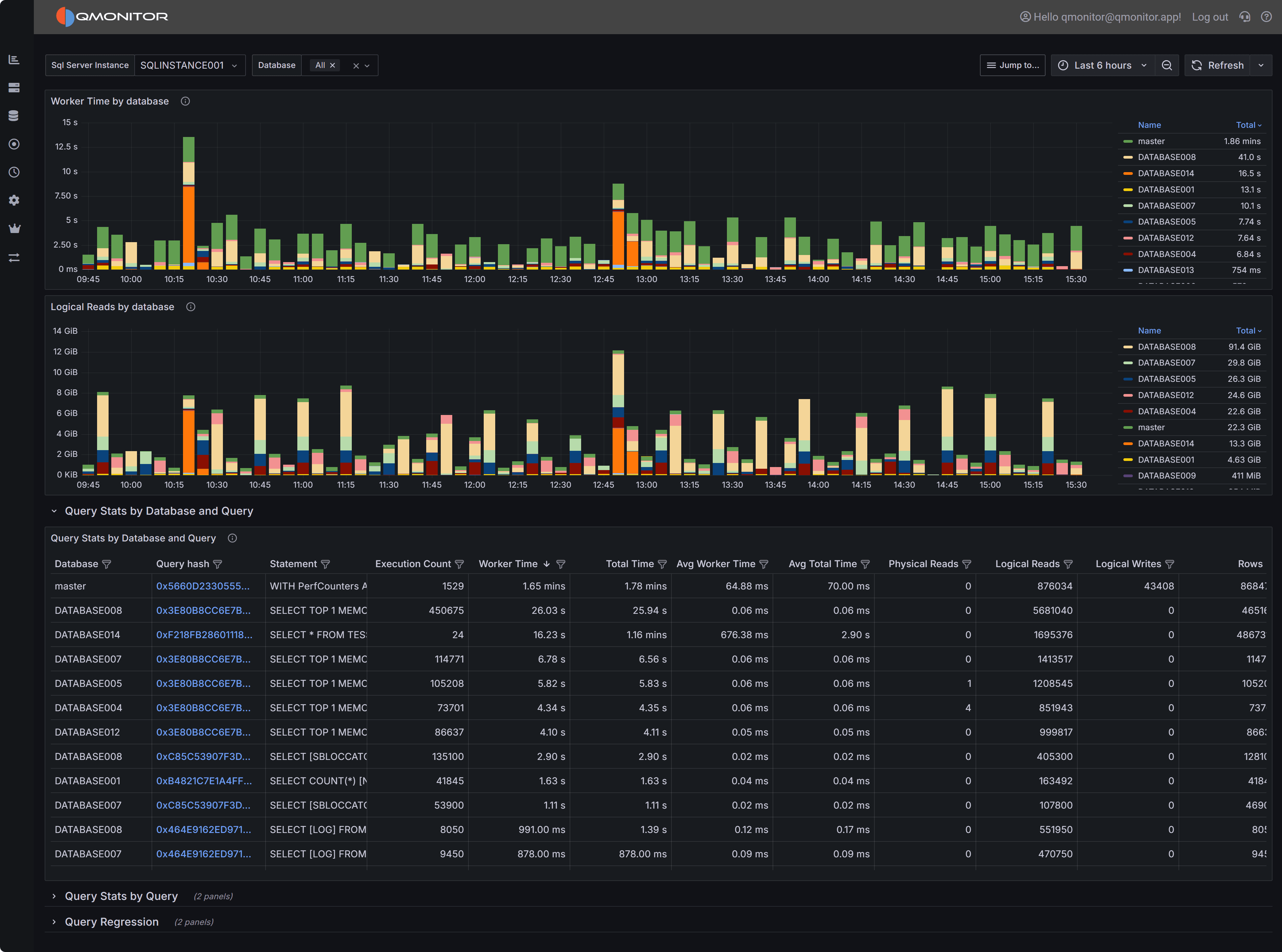
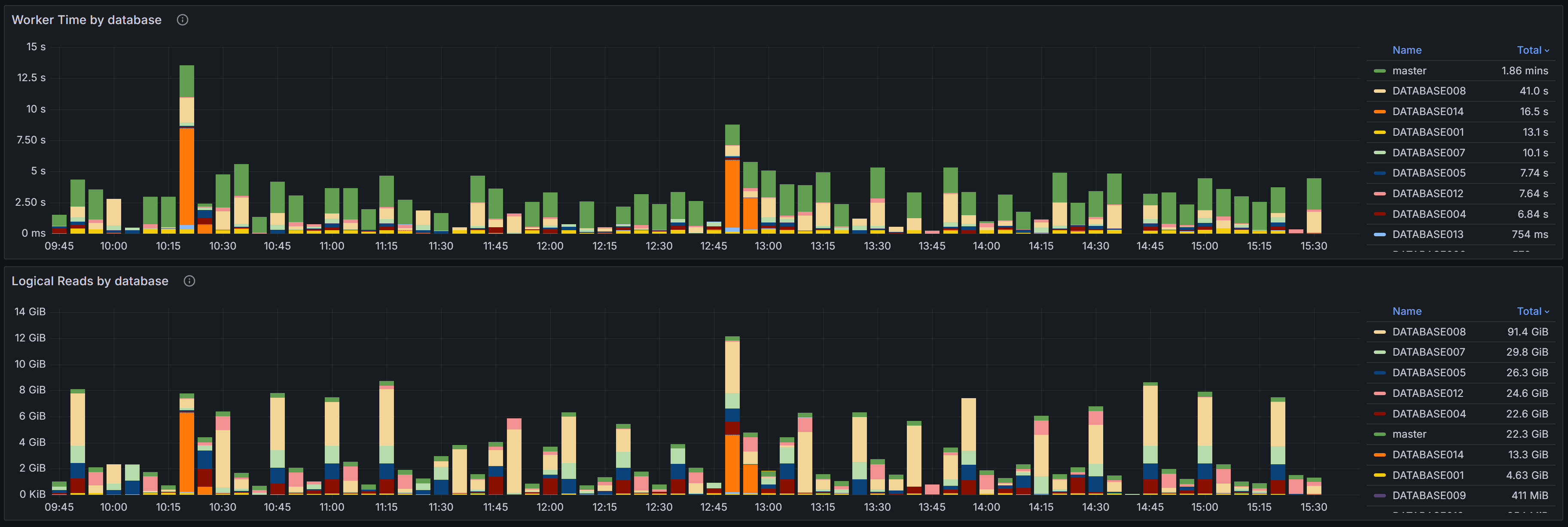
At the top of the dashboard you have two charts that provide a high-level view of resource consumption
across your databases.
 Query Stats Overview
Query Stats Overview
The Worker Time by Database chart shows the cumulative CPU time consumed by queries in each database
during the selected time range. Worker time represents the actual CPU cycles spent executing queries,
making it one of the most important metrics for understanding which databases are driving CPU usage on
your instance. By analyzing this chart over time, you can identify databases that consistently consume
high CPU resources or spot sudden increases that may indicate new workloads or inefficient queries.
This information is valuable when planning capacity, troubleshooting performance issues, or identifying
which databases deserve the most tuning attention.
The Logical Reads by Database chart displays the number of logical page reads performed by queries in
each database. Logical reads measure how many 8KB pages SQL Server accessed from memory or disk to
satisfy query requests. High logical reads indicate either large result sets, missing indexes forcing
table scans, or inefficient query patterns that read more data than necessary. Unlike physical reads
which measure actual disk I/O, logical reads capture all data access regardless of whether the page
was in cache or required a disk read. Databases with high or rising logical reads may suffer from I/O
pressure, especially if memory is limited and pages must be read from disk frequently. Use this chart
to compare databases and track whether optimization efforts are reducing unnecessary data access.
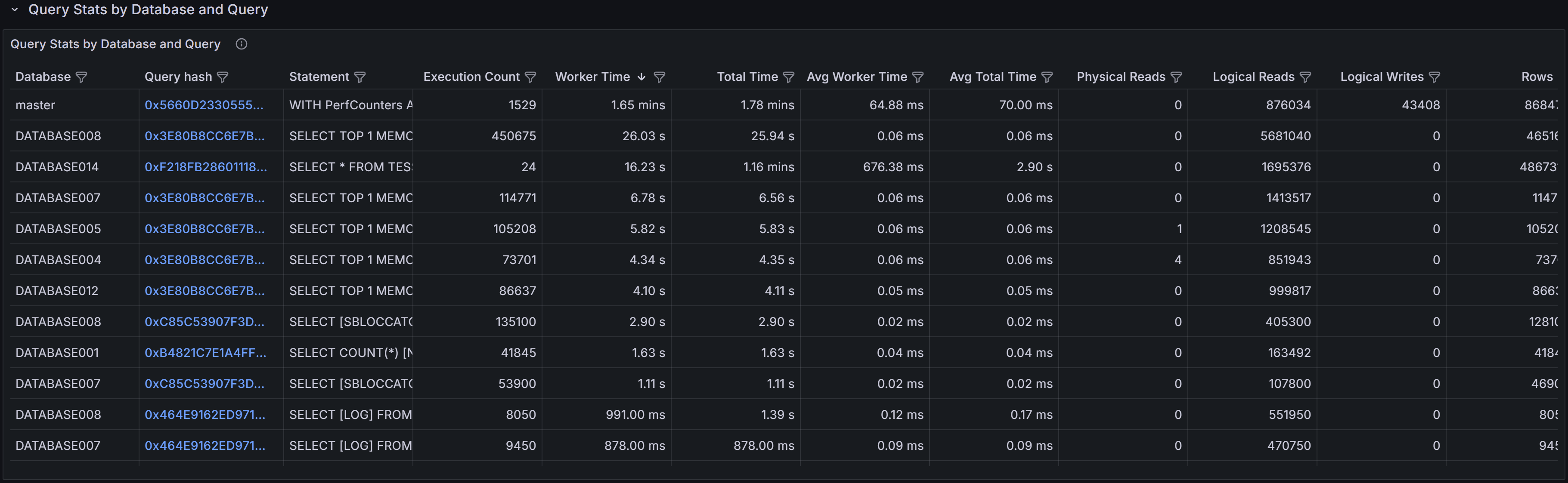
Query Stats by Database and Query
 Query Stats By Database and Query
Query Stats By Database and Query
This section shows the top queries grouped by both database and query text. Each row in the table
represents a specific query running in a specific database, allowing you to drill down into the most
resource-intensive queries within individual databases.
The table includes several key metrics to help you assess query performance. Worker Time displays the
cumulative CPU time consumed by all executions of this query. Logical Reads shows the total number of
pages read from the buffer pool across all executions. Duration represents the total elapsed wall-clock
time for all executions, which may be higher than worker time when queries wait for resources like locks
or I/O. Execution Count tells you how many times the query has run during the selected time period.
Understanding the relationship between these metrics is crucial for effective tuning. A query with high
cumulative worker time and many executions might benefit from better indexing to reduce the cost per
execution. A query with high worker time but few executions may have an inefficient execution plan that
needs rewriting or better statistics. High duration relative to worker time suggests the query spends
significant time waiting rather than executing, pointing to blocking, I/O latency, or resource contention
issues.
Use the filters at the top of the table to narrow your analysis by database name, application name, or
client host. This helps you focus on specific workloads or troubleshoot issues reported by particular
applications. Sort the table by different columns to identify queries with the highest cumulative cost,
longest individual executions, or most frequent execution patterns. Click any row to open the query
detail dashboard where you can examine the full query text, execution plans, and detailed runtime
statistics.
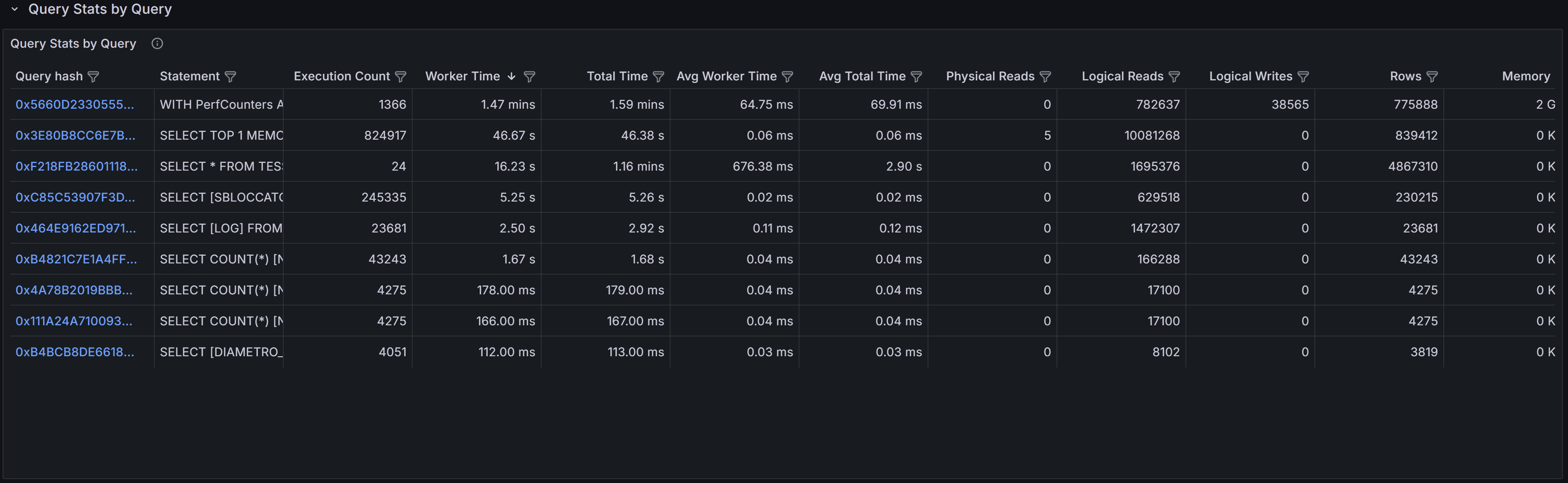
Query Stats by Query
 Query Stats By Query
Query Stats By Query
The Query Stats by Query section aggregates statistics across all databases for queries with identical
or similar text. This view is particularly useful for identifying widely-used queries that appear in
multiple databases, a common pattern in multi-tenant applications where the same queries run against
different tenant databases.
By aggregating across databases, you can see the total impact of a specific query pattern on your entire
instance. A query that seems moderately expensive in a single database might actually be consuming
significant resources when its cumulative cost across dozens of tenant databases is considered. This view
helps you prioritize optimization efforts toward queries that will have the broadest impact across your
infrastructure.
The columns in this table provide both cumulative totals and per-execution averages. Total Worker Time
and Total Logical Reads show the combined cost across all databases and executions, while Average Worker
Time and Average Logical Reads indicate the typical cost of a single execution. High averages suggest
inefficient query plans that need tuning, while high totals with low averages indicate frequently-executed
queries that might benefit from caching, result set optimization, or better application-level batching.
This section is especially valuable for detecting candidates for query parameterization. If you see
similar query text with slightly different literal values appearing as separate entries, these queries
may not be using parameterized queries or prepared statements, leading to plan cache pollution and
increased compilation overhead. Converting these to parameterized queries can reduce CPU usage and
improve plan reuse.
Query Regressions
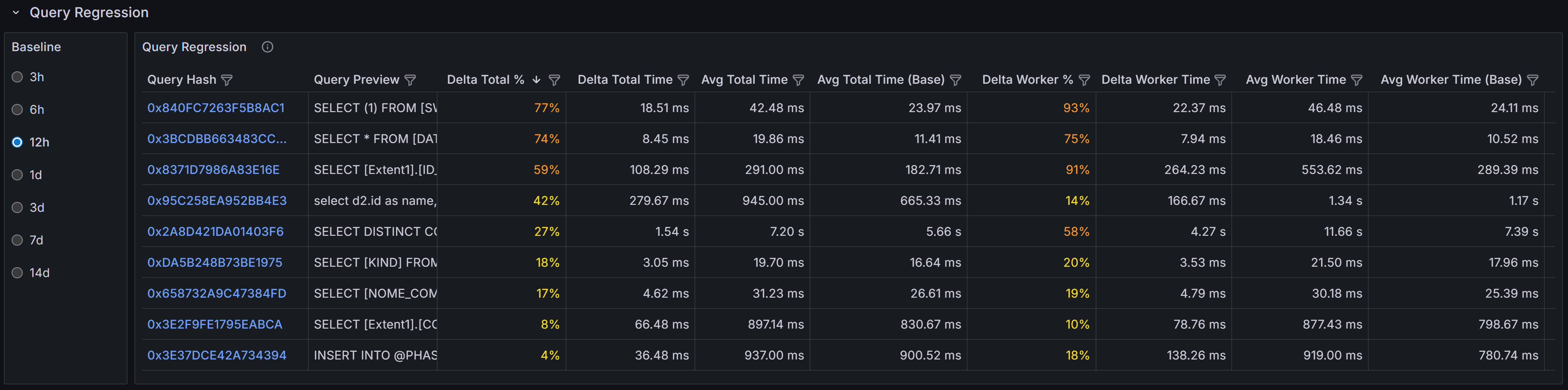 Query Regressions
Query Regressions
The Query Regressions section highlights queries whose performance has degraded significantly compared
to their historical baseline. Performance regressions often occur after SQL Server chooses a different
execution plan due to statistics updates, parameter sniffing issues, schema changes, or increases in
data volume.
This section compares query performance during the selected time window against previous periods to
identify substantial increases in duration, CPU consumption, or logical reads. Regressions are typically
caused by execution plan changes, shifts in data distribution that make existing plans inefficient,
increased blocking as concurrency grows, or resource contention from other workloads. When a query
suddenly takes longer to execute or consumes more CPU than it did previously, investigating the execution
plan history can reveal whether SQL Server switched from an efficient index seek to a costly table scan,
or from a nested loop join to a less optimal hash join.
Click on a query hash value to drill into the detailed execution history for that query. The query detail
view shows historical execution plans, runtime statistics over time, and the complete query text. By
comparing current and historical plans side by side, you can identify exactly what changed and decide
whether to force a specific plan, update statistics, add missing indexes, or rewrite the query to avoid
plan instability.
Query regressions are particularly important to monitor because they represent sudden performance changes
that may not be caused by code changes. A query that worked well for months can suddenly become a
performance problem without any application deployment, making these issues challenging to diagnose
without historical performance data.
Data Sources and Query Store Integration
Query statistics displayed in this dashboard are gathered from two primary sources depending on your
SQL Server configuration and version.
QMonitor continuously captures query execution data through snapshots of the query stats DMVs,
providing query statistics even when Query Store is not available or disabled. This capture
gives you visibility into query performance across all SQL Server versions and editions that QMonitor
supports.
When Query Store is enabled on your databases, QMonitor integrates Query Store data into the
dashboard to provide richer historical information. Query Store is a SQL Server feature introduced in
SQL Server 2016 that automatically captures query execution plans, runtime statistics, and performance
metrics. It is enabled at the database level and retains historical data of query executions,
even for queries that are no longer in the plan cache or are never available in the cache.
Qmonitor tries to rely on query store data when available, but if query store is disabled or
not supported on your SQL Server version, it will fall back to using the query stats DMVs for real-time data.
While you will still see query performance data, you may have less historical plan information and
fewer options for plan comparison. Enabling Query Store on your production databases is recommended
for comprehensive query performance monitoring and troubleshooting.
1 - Query Stats Detail
Detailed statistics about a specific SQL server query
The Query Stats Detail dashboard focuses on a single query and shows how each compiled plan for that
query performed over the selected time interval. This dashboard is your primary tool for understanding
query performance variations, comparing execution plans, and diagnosing performance issues at the
individual query level.
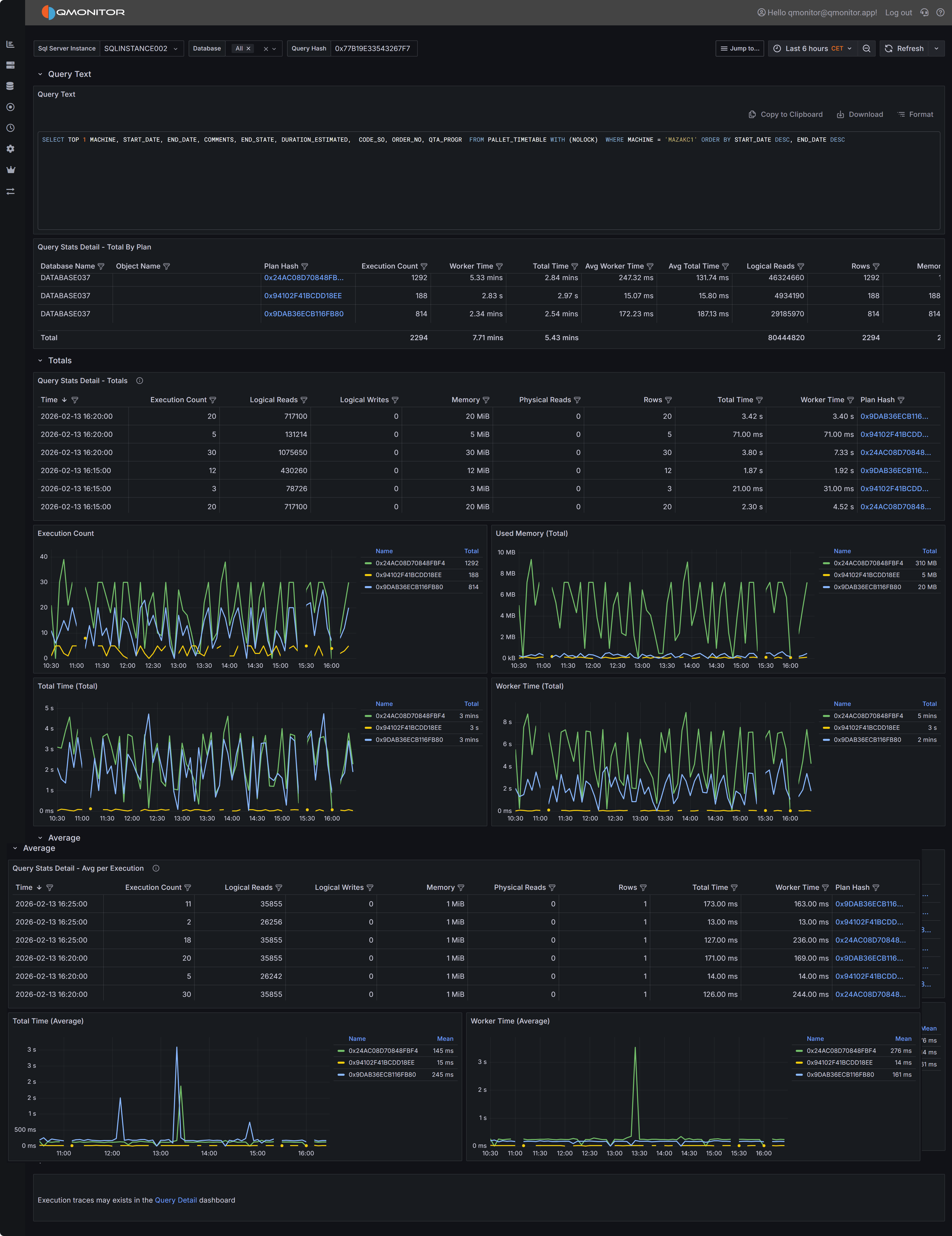 Query Stats Detail dashboard showing query text, plan summaries, and performance metrics
Query Stats Detail dashboard showing query text, plan summaries, and performance metrics
Dashboard Sections
Query Text Display
At the top of the dashboard you will find the complete SQL text for the query you are investigating.
 Query text display with copy, download, and format controls
Query text display with copy, download, and format controls
The toolbar above the query text provides several useful functions. The copy button allows you to quickly
copy the entire query text to your clipboard so you can paste it into SQL Server Management Studio or
another query editor for testing and optimization. The download button saves the query text as a SQL file
to your local machine, which is useful when you need to share the query with colleagues or save it for
documentation purposes. The format button reformats the query text with proper indentation and line breaks,
making complex queries easier to read and understand. Properly formatted queries are particularly helpful
when analyzing deeply nested subqueries or queries with many joins and predicates.
Plans Summary Table (Totals by Plan)
The Plans Summary table provides a high-level comparison of all execution plans that SQL Server has
compiled for this query during the selected time range. Each row in the table represents a distinct
execution plan, identified by its plan hash value.
 Plans summary showing execution counts and performance metrics for each plan
Plans summary showing execution counts and performance metrics for each plan
The table includes several key metrics to help you compare plan performance.
- Database Name indicates which database the query ran in
- Object Name shows the name of the stored procedure, function, or view that contains the query, if applicable.
- Execution Count shows how many times each plan was executed during the time range.
- Worker Time displays the total CPU time consumed by all executions of this plan.
- Total Time represents the total elapsed wall-clock time, which includes both execution time and
any waiting time for resources.
- Average Worker Time and Average Total Time show the per-execution cost, helping you identify
plans that are individually expensive versus plans that accumulate high cost through frequent execution.
- Rows indicates the number of rows returned by the query, which can help you identify whether
different plans are returning different result sets or processing different amounts of data.
- Memory Grant shows the total memory allocated to executions of this plan.
This table is particularly valuable for identifying plan variations and understanding their performance
impact. If you see multiple plans with significantly different performance characteristics for the same
query text, this often indicates parameter sniffing issues where SQL Server cached different plans
optimized for different parameter values. Plans with high average worker time or total time deserve
investigation to understand what makes them expensive. Plans with very high execution counts but low
average cost might benefit from application-level caching or query result reuse rather than query-level
optimization.
Totals Section
The Totals section displays time-series data showing how query performance varied over the selected time
range. The data is aggregated into 5-minute buckets, with each row representing the cumulative metrics
for all query executions that occurred during that 5-minute period.
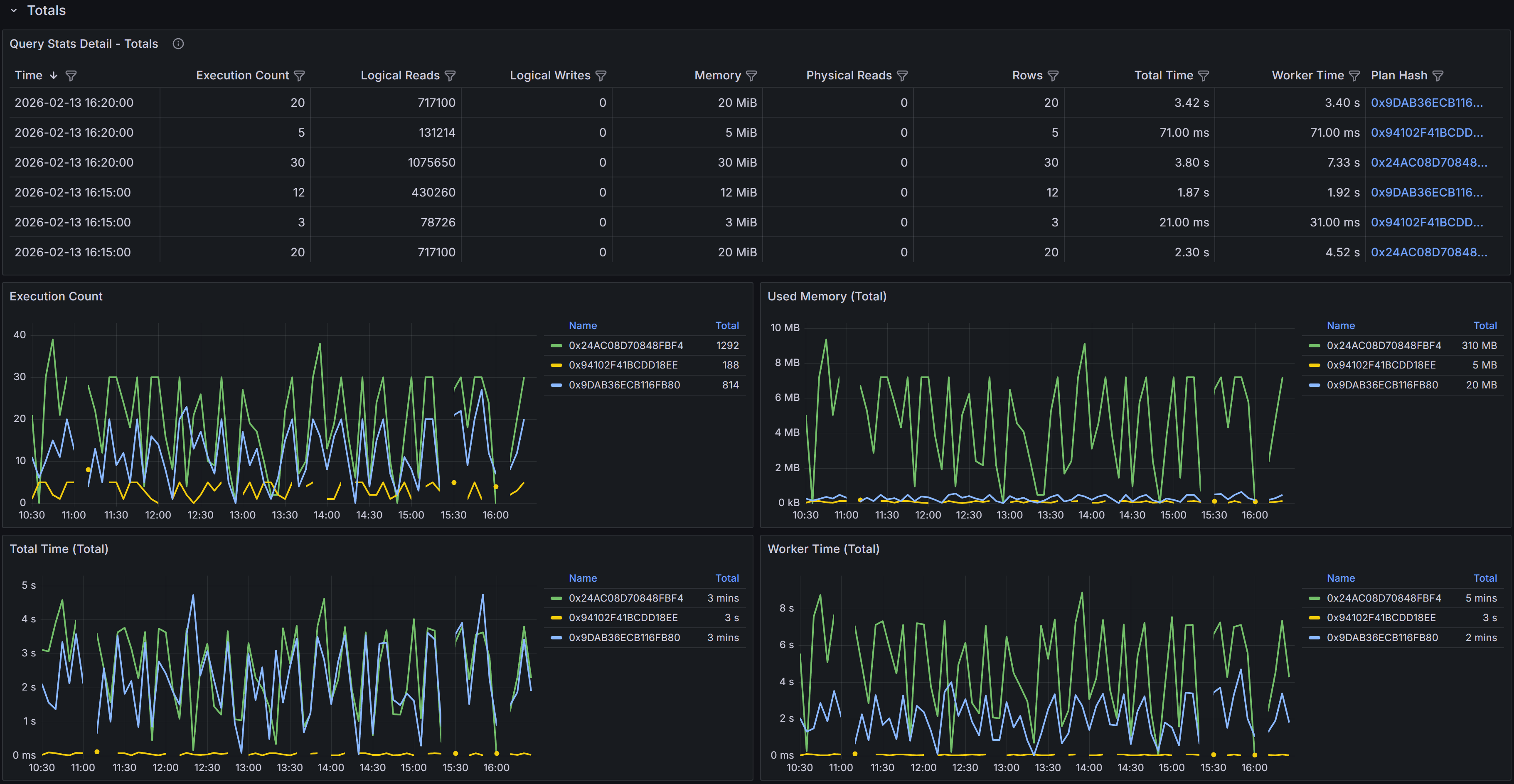 Time-series table and charts showing cumulative query performance metrics
Time-series table and charts showing cumulative query performance metrics
The time-series table includes detailed metrics for each 5-minute bucket.
- Time shows when the 5-minute bucket started.
- Execution Count indicates how many times the query ran during that period.
- Logical Reads displays the total number of 8KB pages read from memory during all executions in the bucket.
- Logical Writes shows the total pages written.
- Memory represents the cumulative memory grants for all executions.
- Physical Reads indicates how many pages had to be read from disk because they were not in the buffer cache.
- Rows shows the total number of rows returned by all executions.
- Total Time represents the cumulative elapsed time for all executions
- Worker Time shows the cumulative CPU time.
- Plan Hash identifies which plan was used during each sample period.
The Plan Hash values in the table are clickable links. When you click a plan hash, QMonitor downloads
the execution plan as a .sqlplan file that you can open in SQL Server Management Studio.
The charts in the Totals section visualize how query performance varied over time and how different plans
contributed to resource consumption. The Execution Count by Plan chart shows how frequently each plan was
executed during each time bucket, helping you understand plan usage patterns. The Memory by Plan chart
displays memory grant trends, which is valuable for identifying queries that request excessive memory or
queries whose memory requirements vary significantly over time. The Total Time by Plan and Worker Time
by Plan charts show how much elapsed time and CPU time each plan consumed, making it easy to spot periods
when query performance degraded or when a particular plan dominated resource usage.
Tip
Use these charts to identify performance patterns and correlate them with other events. If you see a sudden
spike in worker time or total time at a specific point in time, you can investigate what changed at that
moment. Did SQL Server switch to a different execution plan? Did the query start receiving different
parameter values? Did concurrent workload increase and cause resource contention? The time-series view
provides the temporal context needed to answer these questions.Averages Section
The Averages section presents the same time-series data as the Totals section, but with metrics averaged
per execution rather than aggregated cumulatively. This view is particularly valuable for understanding
the per-execution cost of the query and identifying when individual executions became more expensive.
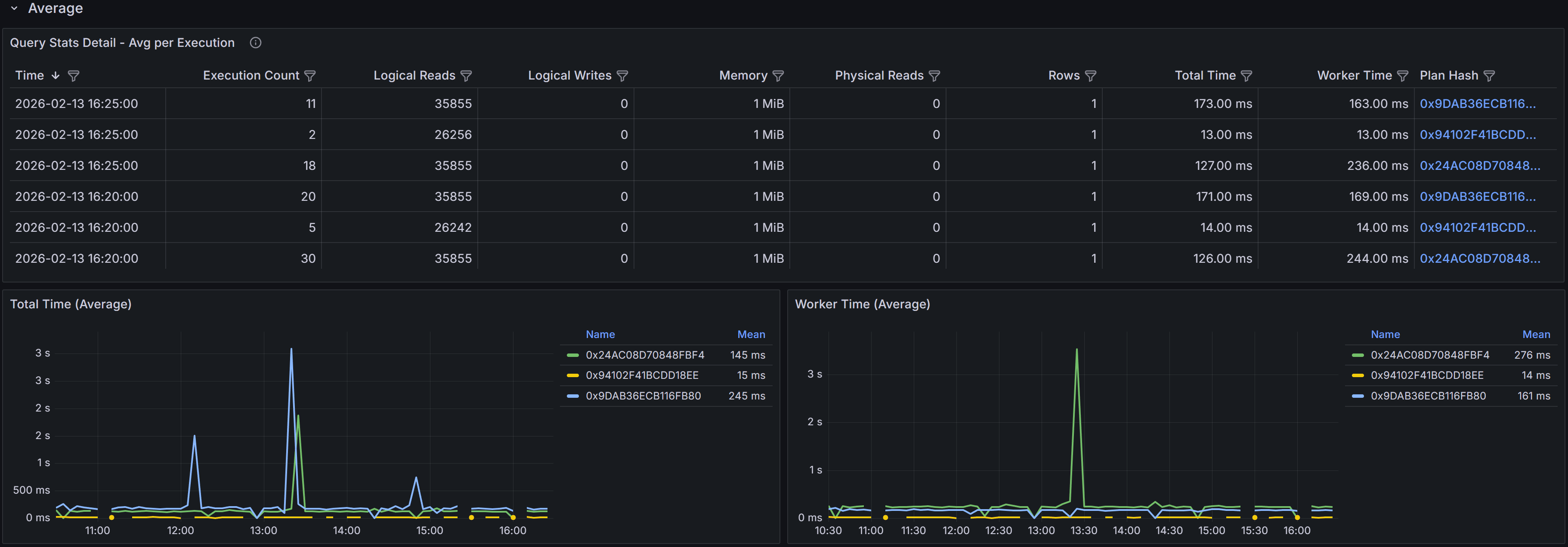 Time-series table and charts showing average per-execution metrics
Time-series table and charts showing average per-execution metrics
The time-series table in the Averages section shows metrics averaged across all executions that occurred
during each 5-minute bucket. For example, if the query executed 100 times during a 5-minute period with
a total worker time of 50,000 milliseconds, the average worker time would be 500 milliseconds per execution.
This per-execution perspective helps you identify whether query performance degradation is due to the
query becoming inherently more expensive or simply running more frequently.
The columns mirror those in the Totals table: Sample Time, Execution Count, averaged Logical Reads,
Logical Writes, Memory, Physical Reads, Rows, Total Time, Worker Time, and Plan Hash. The Execution Count
is not averaged since it represents the number of times the query ran, but all other metrics show the
average value per execution during that time bucket.
The charts in the Averages section focus on per-execution cost trends. The Total Time (avg) by Plan chart
shows how the average elapsed time per execution varied over time for each plan. The Worker Time (avg) by
Plan chart displays the average CPU time per execution. These charts help you distinguish between
performance issues caused by increased query frequency versus issues caused by increased per-execution cost.
Example
For example, if the Totals section shows high cumulative worker time but the Averages section shows low
average worker time per execution, the high total cost is due to query frequency rather than query
efficiency. In this case, application-level solutions like caching, query result reuse, or reducing
unnecessary query executions might be more effective than query optimization.
Conversely, if the Averages
section shows high per-execution cost, the query itself is expensive and needs optimization through better
indexes, query rewrites, or plan improvements.
When analyzing query performance using this dashboard, start by examining the Plans Summary table to
understand how many distinct plans exist for the query and whether any plans are significantly more
expensive than others. Multiple plans with different performance characteristics often indicate parameter
sniffing issues where SQL Server cached plans optimized for specific parameter values that may not be
optimal for all parameter combinations.
Use the Totals and Averages charts together to understand performance patterns. High totals with low
averages suggest the query runs frequently but each execution is relatively cheap, pointing to
application-level optimization opportunities. High averages indicate expensive individual executions that
need query-level optimization. Comparing performance across different time periods helps you identify
whether performance degradation was gradual or sudden, which provides clues about the root cause.
Using the Dashboard Effectively
Set the time range selector to focus on the period when performance issues occurred. If you are
investigating a regression that started yesterday, select a time range that includes both before and after
the regression so you can compare plan behavior and metrics. For ongoing performance issues, use a recent
time range like the last few hours to analyze current behavior.
Sort and filter the time-series tables to focus on specific time periods or plans. If you know that
performance degraded at a specific time, filter the table to show only samples from that period. If you
want to compare two different plans, filter by plan hash to isolate their metrics.
Download multiple execution plans when comparing plan variations. Open them side by side in SQL Server
Management Studio to identify exactly what changed between plans. Look for differences in join types,
index selection, join order, and operator choices. Understanding why SQL Server chose different plans
helps you decide whether to update statistics, add indexes, use query hints, or enable plan forcing.
When you identify a specific plan that performs best, consider using Query Store plan forcing to lock the
query to that plan. This prevents SQL Server from choosing suboptimal plans in the future, providing
stable and predictable performance. However, plan forcing should be used carefully and monitored regularly,
as data volume changes or schema changes may eventually make the forced plan suboptimal.
Compare Totals and Averages to determine whether optimization efforts should focus on reducing per-execution
cost or reducing execution frequency. If totals are high but averages are low, work with application teams
to reduce unnecessary query executions, implement caching, or batch operations. If averages are high, focus
on database-level optimization like indexes, query rewrites, or schema changes.